Introducing Role-Based Access Control (RBAC)
Granular Permissions with Role-Based Access Control (RBAC)
We’re excited to announce the launch of our new Role-Based Access Control (RBAC) system, giving you precise control over who can access and manage your resources.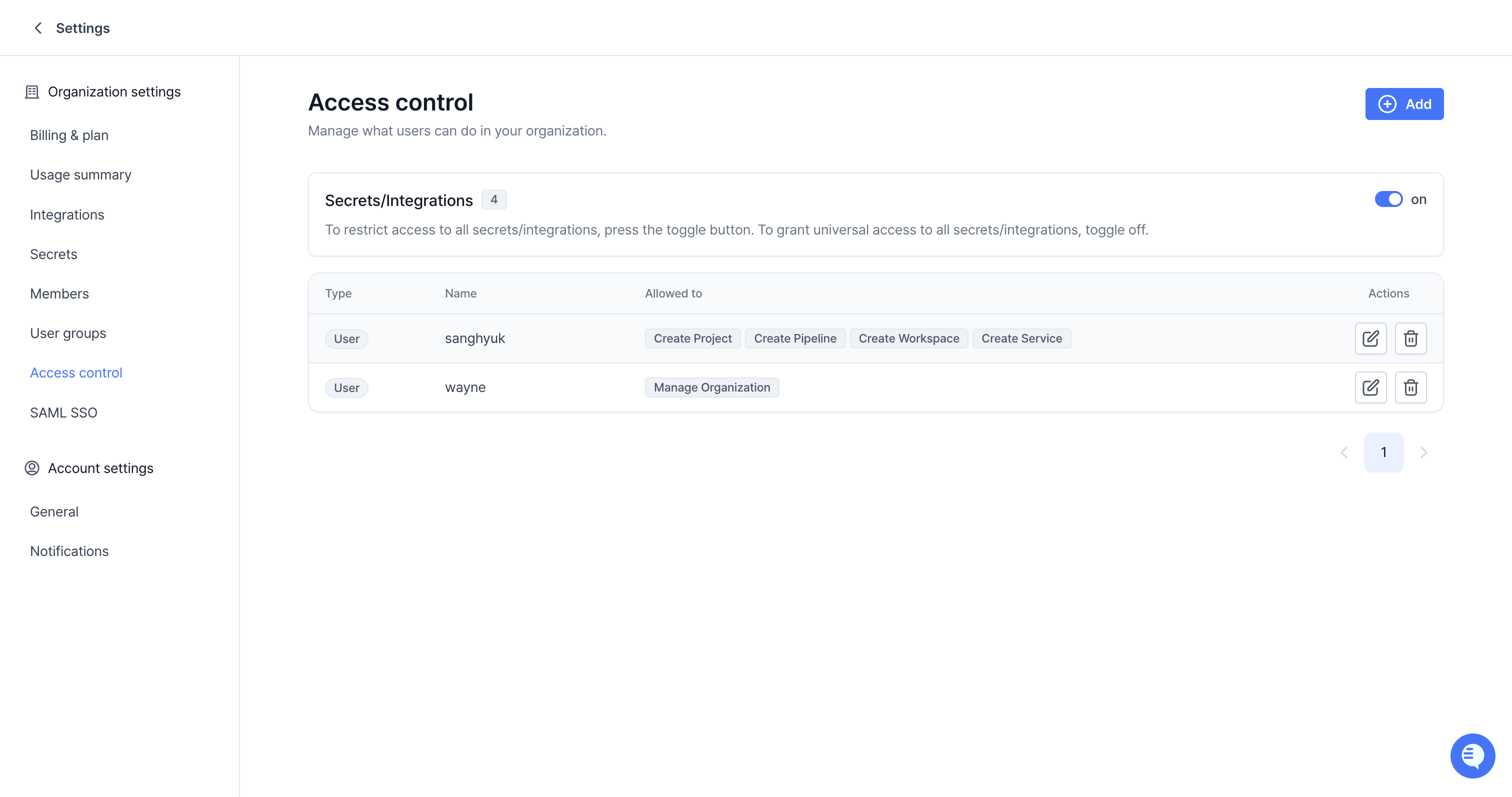
Key Updates
- Fine-Grained Permissions: Assign specific permissions for Projects, Workspaces, Pipelines, Services, Storages, and Volumes.
- User Groups: Streamline permission management by assigning roles to groups of users.
- Default
everyoneGroup: A built-in group that includes all members of your organization for easy, broad-level access configuration. - Assume Subject for Pipelines and Services: Run Pipelines and Services with the permissions of a designated user or group, ensuring consistent and secure execution.
- New
Access ControlTab: Manage all permissions from a centralized Access control tab available for each resource.
Public Hub 2.0 UI refresh & Pipeline Template rollout
New Hub, New Pipeline Templates — Public Hub 2.0 + Pipeline Templates
The Hub experience has level-upped.You can now browse Pipeline templates alongside classic Run and Service templates, with a brand-new UI that makes discovery effortless.
Quickstart
- Open Public Hub → Pipelines and pick a template.
- Review the DAG, choose resources, and hit Publish.
- Enterprise teams: switch to Private Hub to create and publish your own.
Heads-up: Only VESSL can publish templates to Public Hub. Your organization retains full control inside Private Hubs.
GCP & AWS Managed-Cluster Support Sunset
Deprecation notice — VESSL-managed AWS & GCP clusters
VESSL Cloud’s AWS / GCP managed-cluster service is being retired.Next steps
- Review active workloads in Console → Clusters.
- Migrate or back up data before the deadlines.
- Launch new production jobs on Oracle Cloud Infrastructure (OCI) or on-prem/private clusters.
- We’ll reach out to you through an official announcement and email to ensure you have the necessary information and support. Thank you for your understanding and support. We are committed to providing you with the best possible experience on VESSL.
Launching Private Hub, accessing an AI development template internally
Key updates
Private Hub enables:- Templatizing YAML configurations
- Sharing templates privately
SAML SSO Integration
Key updates
-
Introducing SAML SSO support
- VESSL now supports SAML 2.0 for single sign-on, enabling seamless login through external identity providers (for example, Microsoft Entra, Okta, or custom providers).
- Simplifies user management at scale by centralizing access control through your identity provider.
-
Streamlined configuration
- Metadata URLs for VESSL and common IdPs allow quick setup.
- Only HTTP-POST bindings for the Assertion Consumer Service (ACS) are supported at this time.
-
Limitations
- IdP-initiated SSO and IdP-initiated Single Logout (SLO) are not currently supported.
- Requires specifying the correct IdP attributes (user ID and user email) to map your organization’s users in VESSL.
-
Interactive demo
- We’ve included an interactive guide in our SSO Settings page, helping you configure SAML SSO in just a few clicks.
User onboarding process enhancement
Key updates
-
Onboarding process enhancement
- We’ve enhanced the onboarding process to help new users get started with VESSL more efficiently.
- Previously, the onboarding experience could be challenging. This update introduces a more streamlined and guided process to improve user experience.
- The new onboarding features include interactive tutorials, step-by-step instructions, and contextual help, starting with VESSL Run. Updates for VESSL Workspace, Service, and Pipeline are coming soon.
- As a bonus, users completing the onboarding process will receive $5 in additional credits.
App tab added
-
The new App tab has been added to VESSL Run, offering a more user-friendly way to access third-party tools.
- The App tab displays tools using web-based UI frameworks like Gradio, Jupyter, and Streamlit directly within the platform.
- No need to redirect to external pages—just run the app and start working seamlessly.
Logs Refinement
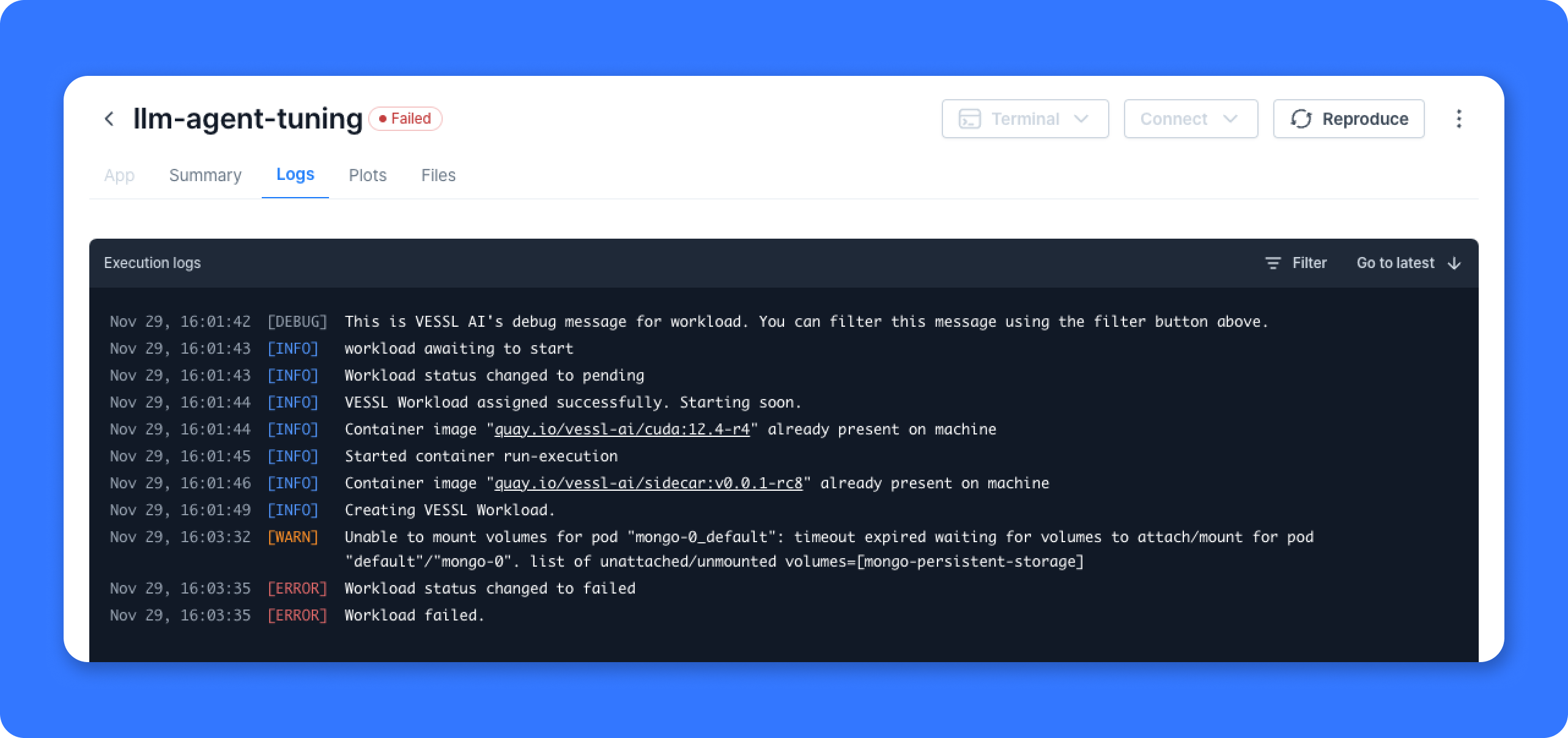
Key updates
- We’ve improved the Logs tab to enhance intuitive understanding.
-
On VESSL, users can now view categorized tags in Logs:
DEBUG,INFO,WARNING, andERROR.- DEBUG: Events that provide information necessary for debugging.
- INFO: Indicates that everything is functioning normally.
-
WARNING: Warning events where the reason is
FailedSchedulingorEvicted. - ERROR: All other warning events. These are error situations where runs or containers fail to start.
- This enhancement enables you to quickly identify what is happening and what might be wrong. When running models or deploying services on VESSL, you can find information in Logs to help handle errors. Additionally, we are notified when users encounter problems, functioning as a hotline so we can assist you as quickly as possible.
This refinement is only available in V2, not V1.
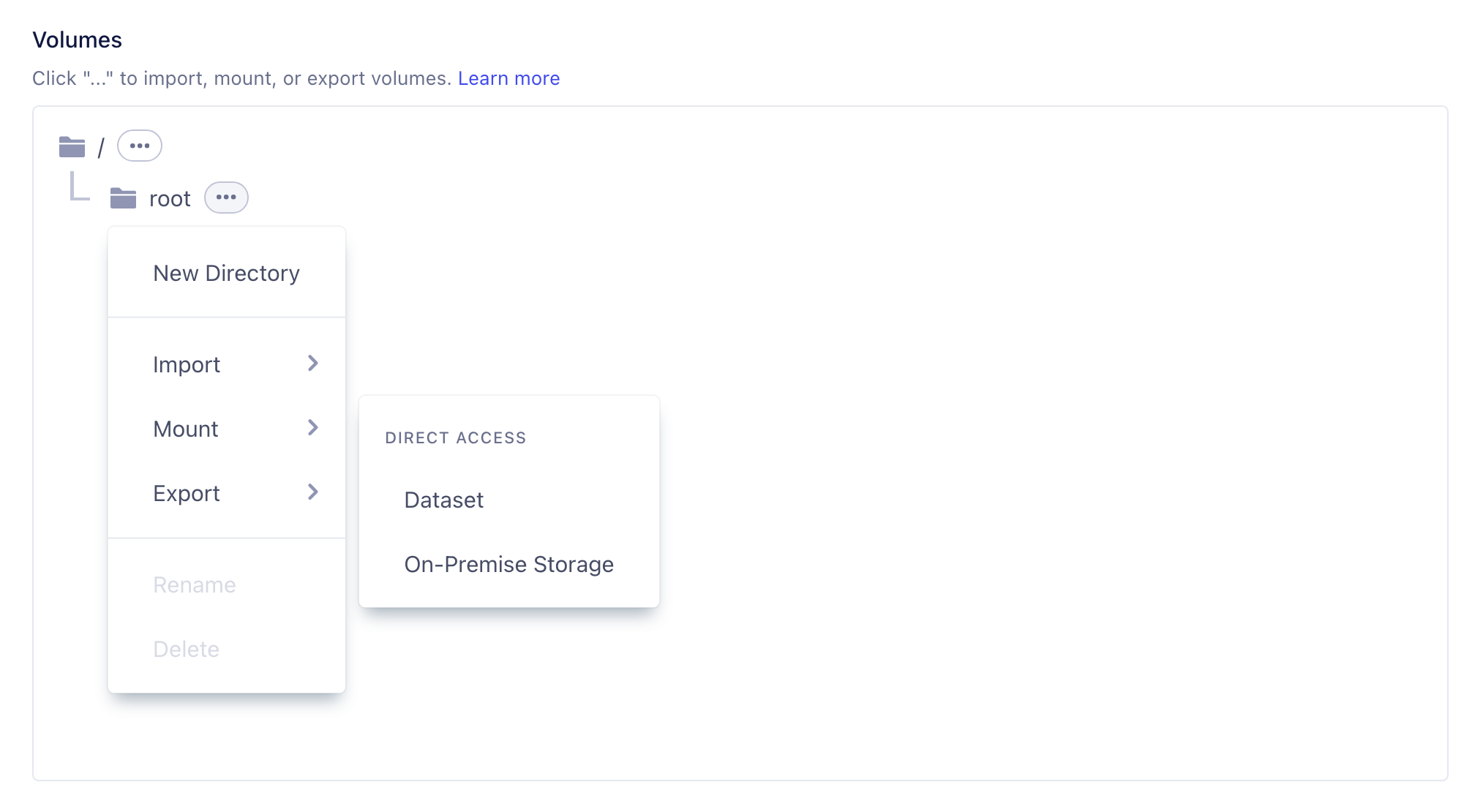
VESSL Storage supports Google Cloud Storage (GCS)
Introducing the All-New VESSL Storage Update
- Ambiguous definitions: The definitions of Storage, Dataset, Model, and Artifact were not clear.
- Complex operations: The methods for importing, mounting, and exporting were not straightforward.
- Unclear artifact functionality: Understanding the function and role of Artifacts was difficult.
Key updates
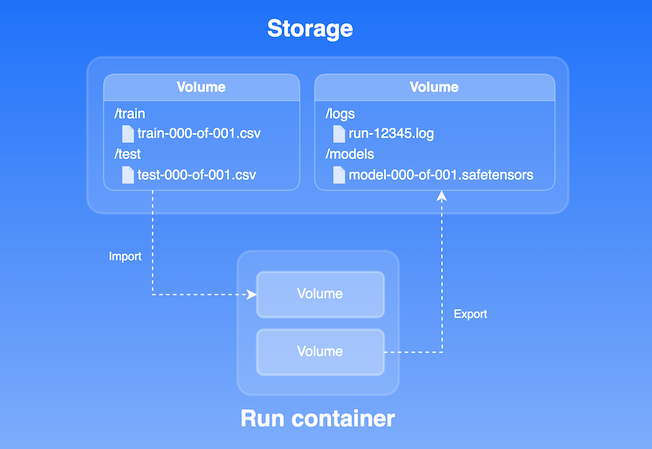
- Unified “Volume” concept: We’ve integrated artifacts, models, logs, and datasets into a single unit called Volume.
- Seamless integration with workloads: Easily integrate Volumes with runs, workspaces, services, and pipelines.
-
Enhanced storage components:
-
Support for VESSL Storage and External Storage: Users can store Volumes in VESSL Storage or external storage solutions like AWS S3, GCP Storage (to be released in early November), and on-premises NFS systems. Files and directories are fully managed in VESSL Storage through automatic storage provisioning.
- VESSL Storage: Optimized for use with VESSL features and ready to use immediately without any integration process.
- External Storage: Allows users to retain data ownership and use data on VESSL without data migration, offering both high security and convenience.
-
Support for VESSL Storage and External Storage: Users can store Volumes in VESSL Storage or external storage solutions like AWS S3, GCP Storage (to be released in early November), and on-premises NFS systems. Files and directories are fully managed in VESSL Storage through automatic storage provisioning.
-
Simplified import, mount, and export operations in the VESSL features:
-
Previous version:
- Import: Code / HuggingFace / Dataset / Model / GCS / S3 / Files / Artifact
-
Current version:
- Import: Code / HuggingFace / Volume / Model
- Mount: Volume / GCS Fuse
- Export: Volume / Model
-
Previous version:
- Manage exported data in Volumes: In VESSL Storage’s Volumes, users can view exported data such as logs, metrics, and model checkpoints from VESSL Runs and Workspaces.
VESSL AI Raises $12M in Series A Funding

CLI update announcement
We have updated our CLI commands to enhance functionality and improve user experience. As part of the recent updates, including the renaming of
VESSL Serve to VESSL Service and the Pipeline GA, the following changes have been made to the VESSL CLI:Deprecated commands
-
vessl serve update -
vessl serve revision list,vessl serve revision show,vessl serve revision terminate -
vessl serve gateway show
New commands
-
vessl service create -
vessl service list -
vessl service read -
vessl service terminate -
vessl service scale -
vessl service split-traffic -
vessl service create-yaml
Notes
- If you have scripts or workflows using the deprecated commands, please update them to use the new commands.
-
For more information on each command, use the
--helpoption. For example:vessl service create --help
Pricing plan section updated in VESSL documentation
We’ve created the pricing plan section in the
Resources section. Also, our pricing plan (GCP, AWS) details have been updated in the VESSL documentation. Users now have more clarity on compute options and corresponding costs. Pro users continue to receive 100 credits every month, with each credit equivalent to $1.00. For more details, refer to the updated Pricing & Compute section in the documentation.Pipeline general availability (GA) update
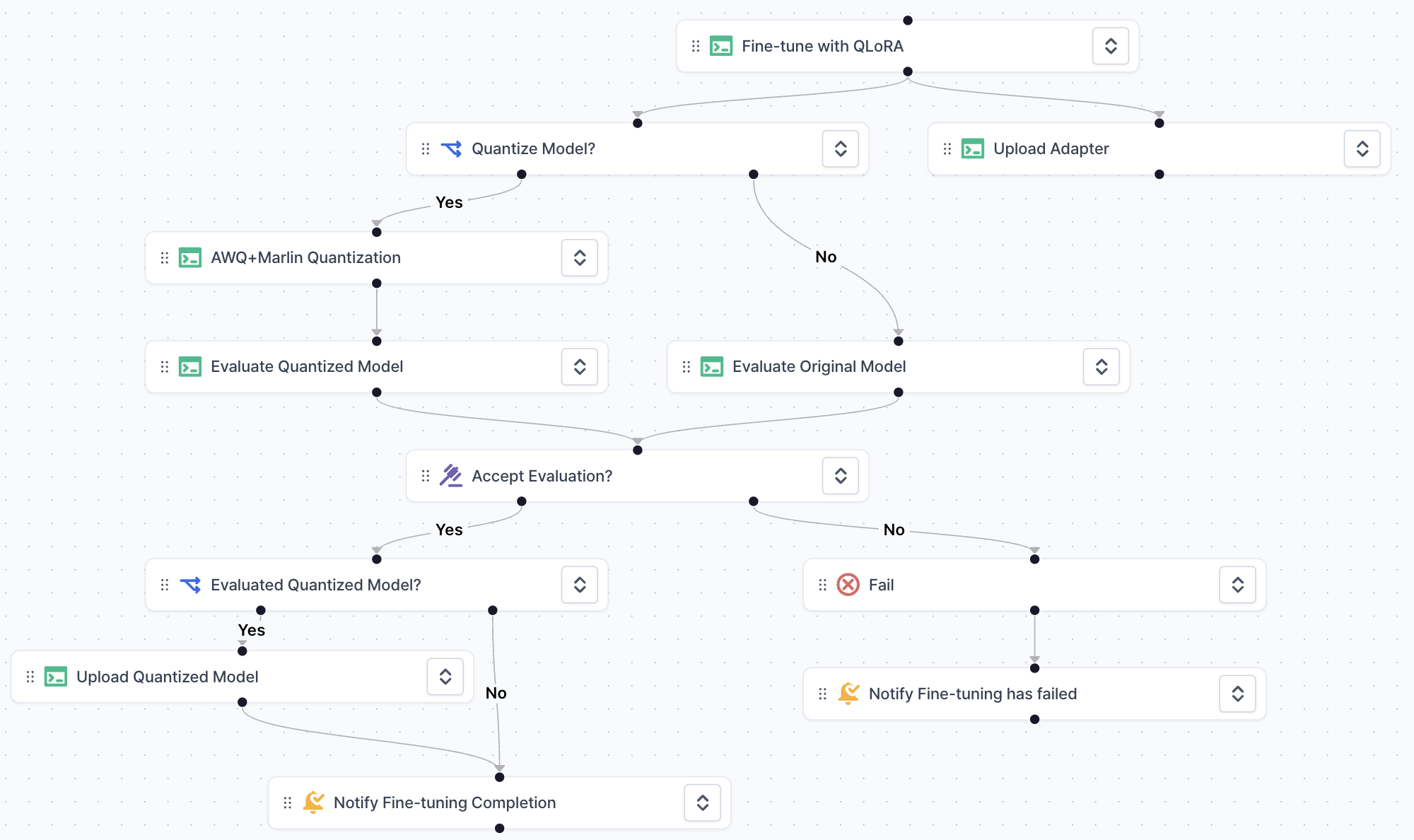
-
Key features:
- Drag-and-drop GUI: Intuitive interface for modifying and visualizing pipeline flows.
- Infra-as-code: YAML-based code interface integration, enabling effective version management of pipeline modifications.
- High visibility and debuggability: Improved debugging capabilities with natural separation of task stages, including endpoint access and re-execution for failed tasks.
- Human-in-the-loop: Built-in support for scenarios requiring user intervention, such as intermediate result feedback and decision-making based on input/output.
Learn more about Pipeline
With the Pipeline section, you can explore it in detail.
Website V2 Update
We are excited to announce the launch of VESSL 2.0, introducing a sleek, user-centric interface designed to streamline the MLOps experience.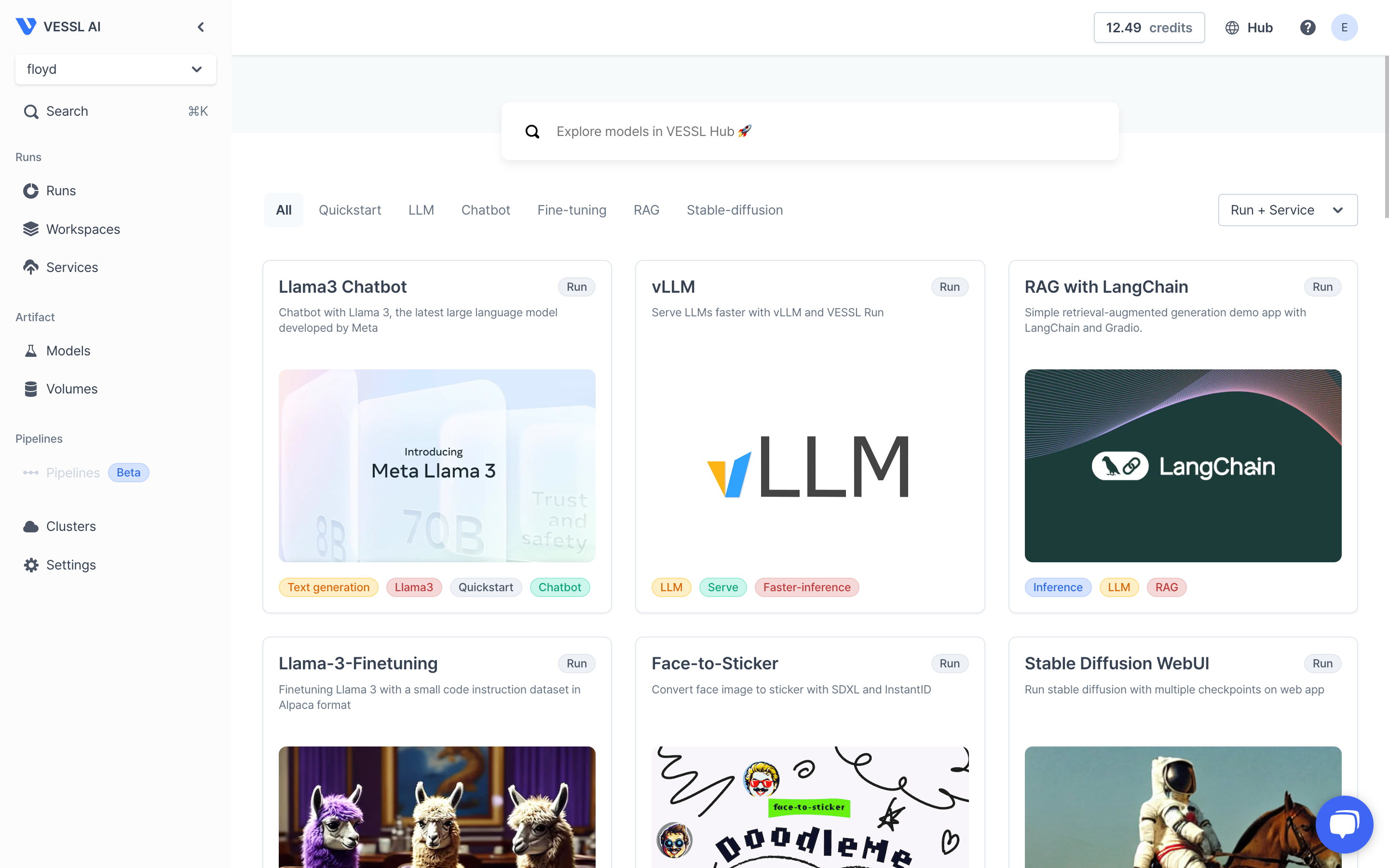
-
New features:
- Self-service user interface: Seamless transition from model exploration to deployment, with tools like VESSL Hub for testing and fine-tuning open-source models, and VESSL Service for creating scalable APIs.
- Service revision creation through web console: Previously only available through CLI, users can now create service revisions in both Provisioned and Serverless Mode through the UI.
- CMD+K navigation: Quick access to any entity within VESSL, enhancing productivity and efficiency.
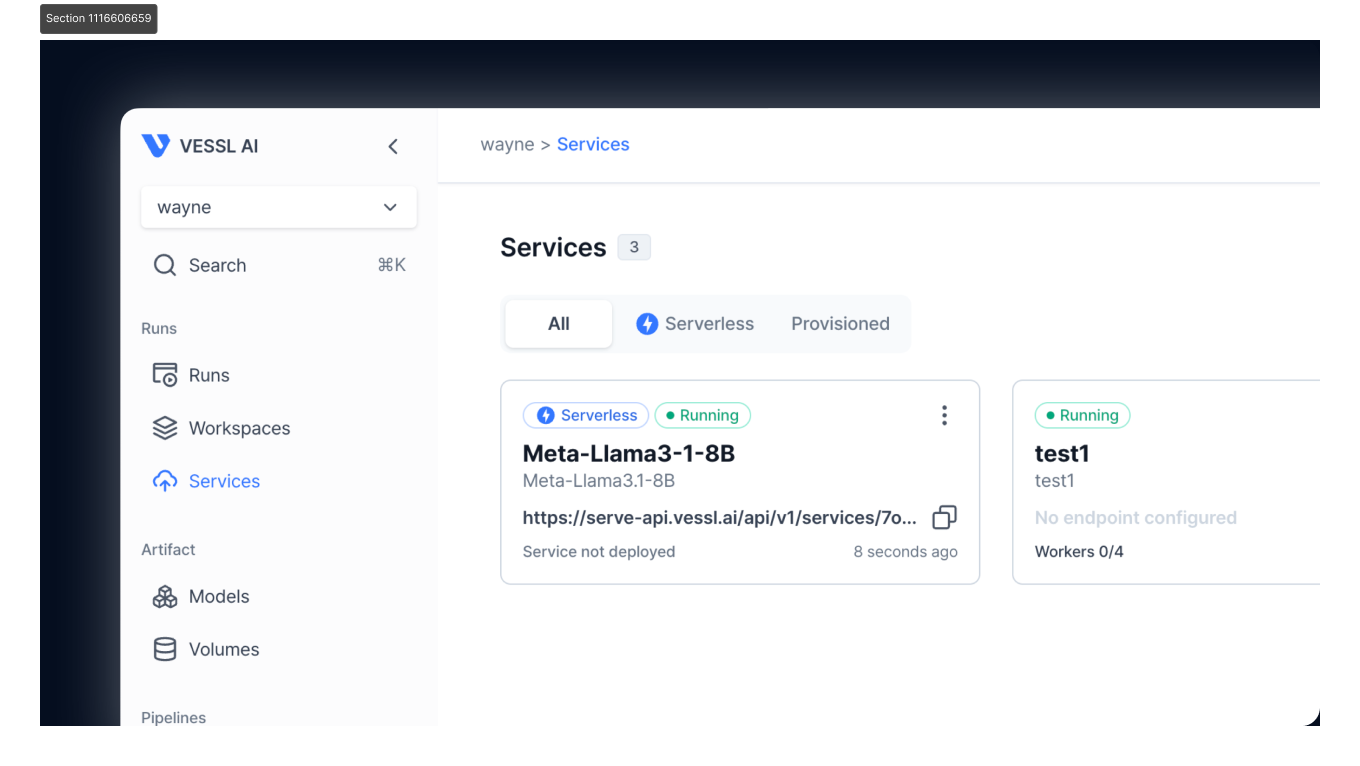
Serverless deployment
-
Key features:
- Cost efficiency: Serverless Mode operates on a scale-to-zero basis, ensuring that users only pay for the resources they actually use.
- Automatic scaling: Real-time scaling based on workload demands without the need for complex configurations.
- Simplified deployment: Minimal configuration required, making deployment accessible to all users.
- High availability and resilience: Fast startup times (average 17 seconds) and robust infrastructure ensure high availability with minimal cold starts.

- Create a remote GPU-accelerated container
- Create an endpoint with Llama 3 from Hugging Face
- Send an HTTPS request to the deployed service
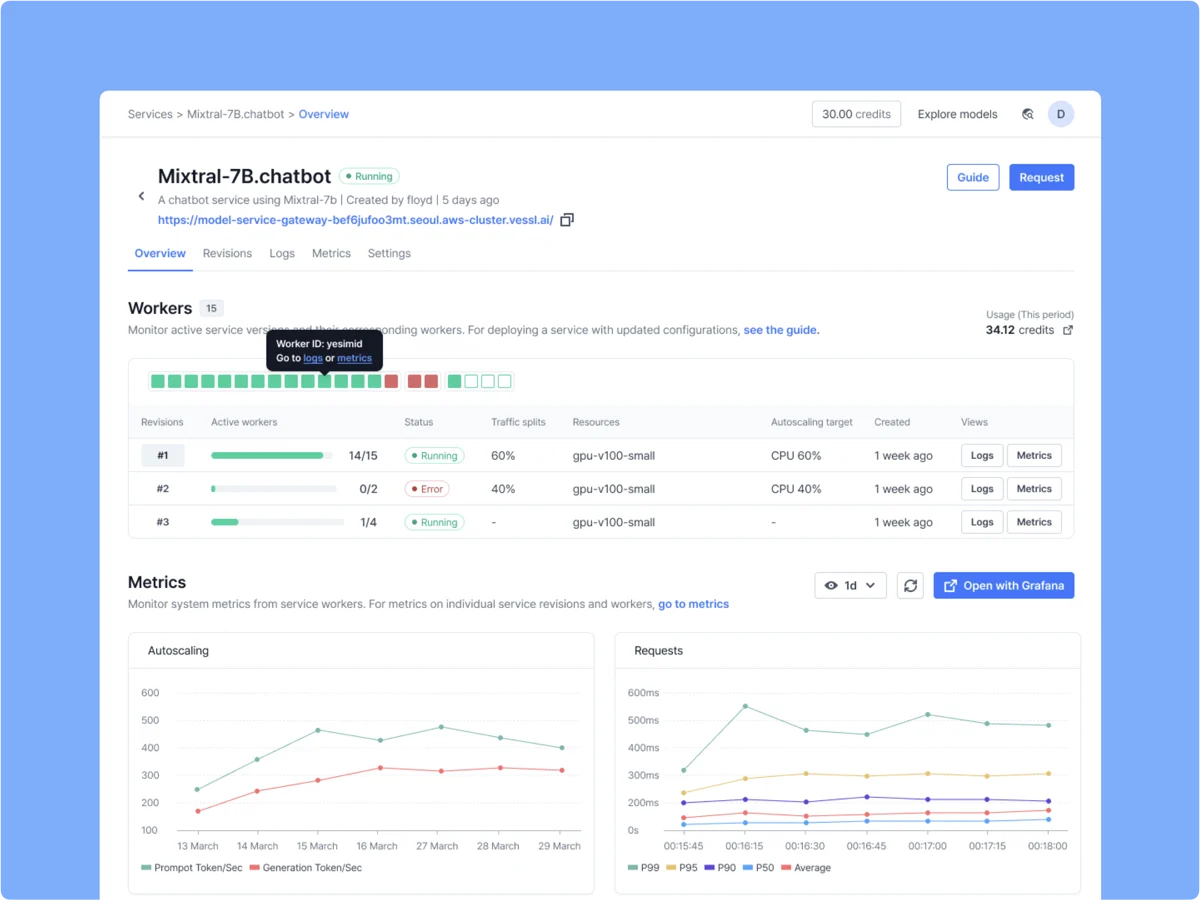
Announcing VESSL Serve
Cloud storage support for VESSL Run
Google Cloud Storage FUSE
We are bringing FUSE support for GCS. FUSE helps you work with object storage through familiar filesystem operations without needing to directly use the proprietary GCS SDKs.New get started guide
New & Improved
- Added a new managed cloud option built on Google Cloud
-
Renamed our default managed Docker images to
torch:2.1.0-cuda12.2-r3
Announcing VESSL Hub