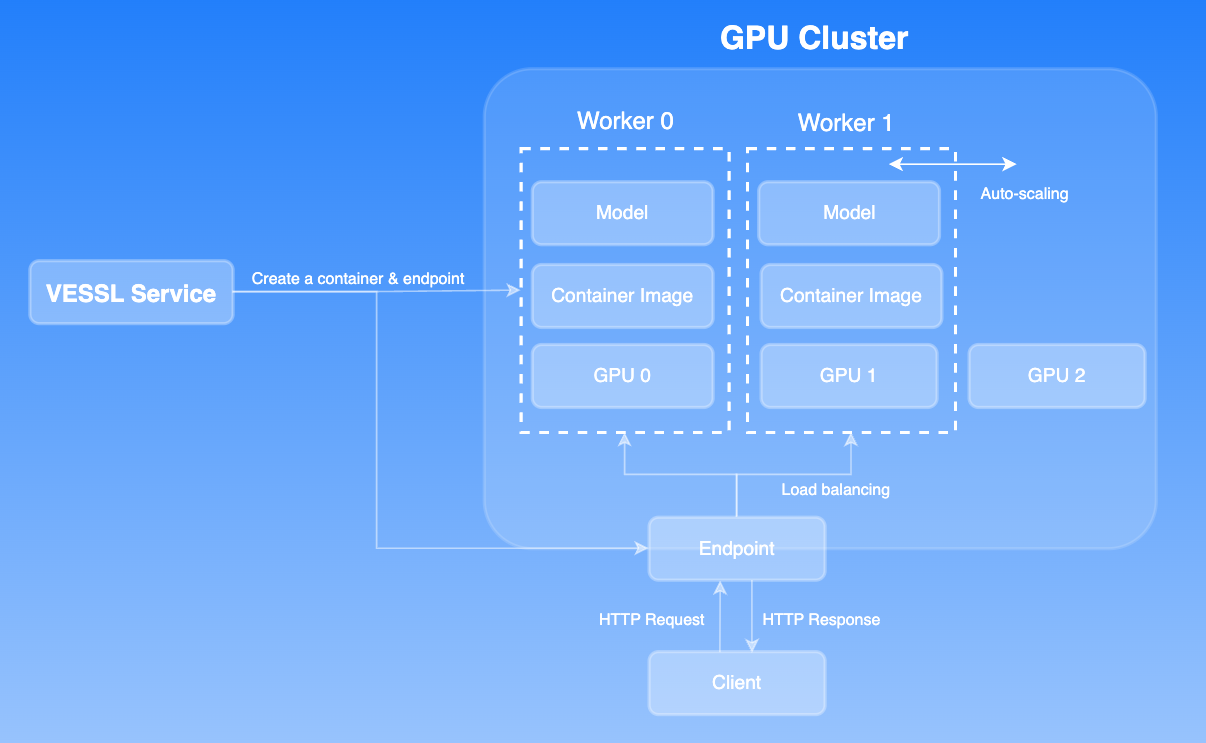
Provisioned mode
VESSL Service acts as a robust platform for deploying models developed within VESSL, or even your custom models, as inference servers. Provisioned Mode is ideal for those who prefer direct control over their deployment environment with features such as:- Activity tracking: Monitor logs, system metrics, and model performance metrics.
- Auto-scaling: Automatically adjust server size based on resource usage to handle increased demands.
- Traffic management: Easily split traffic for Canary testing and gradually roll out new model versions without downtime.
- Operational control: Extensive customization through
YAMLconfigurations for those who need precise control over their deployments.
What’s next in provisioned mode?
VESSL Service Quickstart
Get started with VESSL Service using Llama 3.1-8B and the latest vLLM.
Deploy with YAML
Explore comprehensive
YAML configuration examples.Serverless mode
Serverless Mode simplifies deployments by abstracting away the underlying server management, allowing you to focus solely on model deployment and scaling. It’s particularly beneficial for teams without deep backend management expertise or those seeking cost-efficiency:- Automatic scaling: Scale your models in real-time based on workload demands.
- Cost-efficiency: Only pay for the resources you use with a pay-as-you-go pricing model.
- Simplified deployment: Minimal configuration needed, making it accessible regardless of technical background.
- High availability and resilience: Built-in mechanisms to ensure models are always operational and resilient to failures.
What’s next in serverless mode?
Enable Serverless Mode
Deploy Serverless mode using Text Generation Inference(TGI)
Deploy with YAML
Explore comprehensive
YAML configuration examples.